特性介绍
kube-ovn 提供了针对企业应用场景下容器网络实用功能,并为实现更高级的网络管理控制提供了可能性;现有主要功能:
- 1.Namespace 和子网的绑定,以及子网间的访问控制;
- 2.静态IP分配;
- 3.动态QoS;
- 4.分布式和集中式网关;
- 5.内嵌 LoadBalancer;
- 6.Pod IP对外直接暴露
- 7.流量镜像
- 8.IPv6
默认kubespray 部署kubernetes支持kube-ovn
gin框架,自定义成功返回,错误返回输出
1 | package response |
1 | if ptype == "" { |
1 | <!-- Global site tag (gtag.js) - Google Analytics --> |
kube-proxy 实际上并不起一个 proxy 的作用,而是 watch 变更并更新 iptables,也就是说,client 的请求直接通过 iptables 路由。
如果kube-proxy通过iptables 转发。会修改filter和nat表
filter表通过OUTPUT链规定所有的出报文都要经过KUBE-SERVICES,如果一个Service没有对应的endpoint,则拒绝将报文发出。
例如,创建一个service,下图的frontend,没有对应的endPoint
查看filter:iptables -L -n -t filter
filter表中会将访问172.18.13.31的请求拒绝。
nat表中设置的规则比较多,查看nat表命令:iptables -L -n -t nat
1、在PREROUTING阶段,将所有报文转发到KUBE-SERVICES
2、在OUTPUT阶段,将所有报文转发到KUBE-SERVICES
3、在POSTROUTING阶段,将所有报文转发到KUBE-POSTROUTING
nat表中主要增加了如下几个链-规则

每个Service的每个服务端口都会在Chain KUBE-SERVICES中有一条对应的规则,发送到clusterIP的报文,将会转发到对应的Service的规则链,没有命中ClusterIP的,转发到KUBE-NODEPORTS。
只有发送到被kubernetes占用的端口的报文才会进入KUBE-MARK-MASQ打上标记,并转发到对应的服务规则链。例如第一条划线的KUBE-MARK-MASQ这里分配给SERVICE的端口是3306,该端口的包由kuberentes管理.

而每一个SERVICE,又将报文提交到了各自的KUBE-SEP-XXX。

最后在KUBE-SEP-XX中完整了最终的DNAT,将目的地址转换成了POD的IP和端口。
这里的KUBE-MARK-MASQ为报文打上了标记,表示这个报文是由kubernetes管理的,Kuberntes将会对它进行NAT转换。

KUBE-NODEPORT中,根据目的端口,将报文转发到对应的Service的规则链,然后就如同在“Chain KUBE-SERVICES”中的过程,将报文转发到了对应的POD。

这里表示k8s管理的报文(也就是被标记了0x4000的报文),在离开Node(物理机)的时候需要进行SNAT转换。
也就是POD发出的报文。
1 | (KUBE-SVC@nat) |
也可以理解为从Node发出的报文的处理过程。因为这个数据包是通过本地协议发出的,然后需要更改NAT表,那么k8s就在OUTPUT这个链上来动手。
本例子中ClusterIP为172.18.13.113,对应的pod容器的端口为8080,对应两个pod。
访问命令为curl 172.18.13.113:8082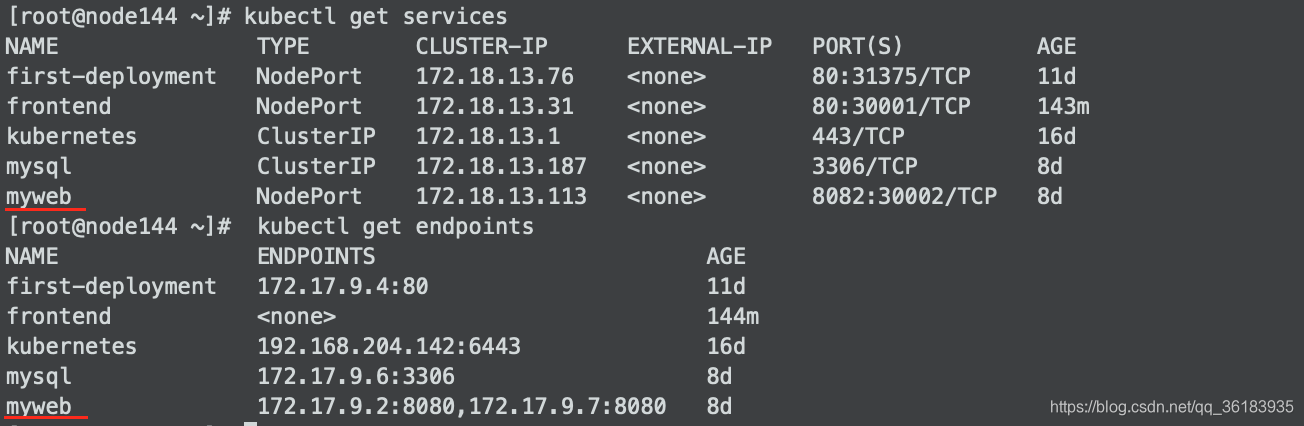
1、经过OUTPUT链时指出报文要经过KUBE-SERVICES
2、在KUBE-SERVICES链查找到ClusterIP-172.18.13.113,于是转发到链KUBE-SVC-YG65S75AKNCDZRSF
3、在KUBE-SVC-YG65S75AKNCDZRSF链中,因为该clusterIP对应两个pod,所有该链下有两条规则,同时实现第一条规则的概率为0.5。
4、假设我们转到了链KUBE-SEP-3BN22EQZG75AYFUY,在该链中对这个包进行了一次DNAT转换,转到172.17.9.2中,即pod的ip地址。
1 | (KUBE-SVC@nat) |
也可以理解为发送到Node的报文的处理过程
其中集群外机器IP为172.18.52.170,pod所在机器为192.168.204.144,暴露在该机器的端口为30002。
访问命令为curl 192.168.204.144:30002
1、集群外机器172.18.52.170根据路由规则将数据包发送到pod所在机器192.168.204.144。
2、数据包进入了pod所在的机器,所以k8s对该机器nat表的PREROUTING链做规则。链时指出报文要经过KUBE-SERVICES。
3、把数据包转到KUBE-SERVICES这个链之后,因为我们是通过nodeport访问的,所有没有匹配到clusterIP,转到KUBE-NODEPORTS链上。
4、KUBE-NODEPORTS还是将数据包转到KUBE-SVC-VZEERQ5BHBSZ5PRL上,打上标签。再转到KUBE-SVC-YG65S75AKNCDZRSF链中,DNAT转换。
通过neutron qos限制虚机上下行带宽
1 | #source admin-openrc.sh |
更多请了解 linux tc
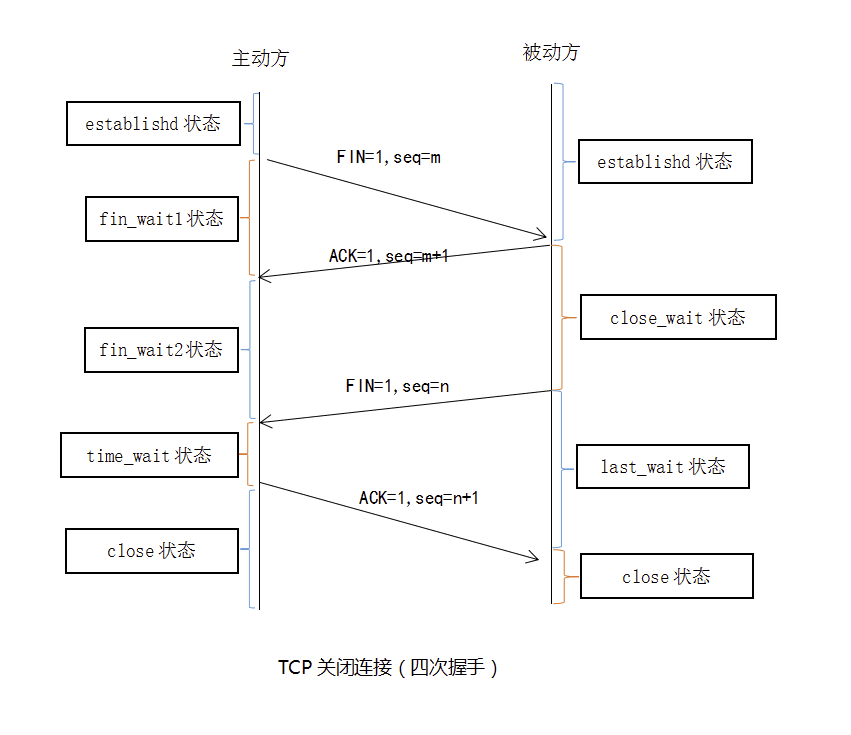
1. 为什么客户端最后还要等待2MSL?

TCP/IP基础,老生常谈的问题了~
TCP/IP 三次握手
所谓三次握手(Three-Way Handshake)即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发,整个流程如下图所示:

(1)第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
SYN攻击:
在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,这些伪造的SYN包将产时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
#netstat -nap | grep SYN_RECV
首先挑选一台能翻墙的CentOS 7 x86_64 服务器
#yum -y install conntrack
#minikube start –driver=none
#minikube kubectl – get pods -A
安装kubectl
#curl -LO “https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl"
#chmod 755 kubectl
#mv kubectl /usr/bin/
安装helm
#curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
查看集群
#kubectl get nodes
在MySQL中删除一张表或一条数据的时候,出现
[Err] 1451 -Cannot delete or update a parent row: a foreign key constraint fails (…)
这是因为MySQL中设置了foreign key关联,造成无法更新或删除数据。可以通过设置FOREIGN_KEY_CHECKS变量来避免这种情况。
我们可以使用
SET FOREIGN_KEY_CHECKS=0;
来禁用外键约束.
之后再用
SET FOREIGN_KEY_CHECKS=1;
来启动外键约束.
查看当前FOREIGN_KEY_CHECKS的值可用如下命令
SELECT @@FOREIGN_KEY_CHECKS;
部署openstack 基于kolla-ansible的方式,架构为鲲鹏 aarch64