elasticsearch 创建索引
PUT /myIndex
传入json
1 | { |
elasticsearch 创建索引
PUT /myIndex
传入json
1 | { |
一台服务器,free -g 查看used 200多G ,可是ps查看进程占用内存,最多也就占用几十G,什么鬼?
检查主机上大页缓存设置:
sysctl -a | grep nr_hugepages
1 | vm.nr_hugepages = 300 |
发现居然配置了大页内存
于是
1 | #vi /etc/sysctl.conf |
恢复正常了
1 | total used free shared buff/cache available |
openstack集群nova/neutron等组件,经常报mysql lost connection 错误,非常烦人,具体报错如下
1 | (Background on this error at: http://sqlalche.me/e/e3q8) |
这是什么原因呢? 分析如下:
从报错信息能看到是查询时和数据库mysql丢了连接? 为什么?
因为openstack组件连接数据库使用oslo_db,封装的基于sqlalchemy的连接池,所以怀疑是连接池里的连接没有回收,导致使用了过期的连接。
上代码:
#vi /var/lib/kolla/venv/lib/python2.7/site-packages/oslo_db/options.py
1 | cfg.IntOpt( |
默认回收时间3600s, 但是我的mysql wait_time 为 1800s,所以只需mysql wait_timeout 大于回收时间就行拉
done~
第一次尝试使用 elastics的go sdk “github.com/olivere/elastic” ,有go版本的真不错,
不料却报错了
1 | panic: elastic: Error 400 (Bad Request): all shards failed [type=search_phase_execution_exception] |
上代码吧
1 | package main |
当使用到Field 精准匹配相关的查询时,所以查询的关键字在es上的类型,必须是keyword而不能是text,比如你的搜索条件是 ”programname”:”neutron”,那么该programname 字段的es类型得是keyword,而不能是text
改成使用 elastic.NewValueCountAggregation().Field(“programname.keyword”) 就可以了
qemu启动虚机,driver使用基于spdk的vhost-user-scsi技术, bdev backend为ceph rbd
创建vhost device (上文创建rbd dev名称为Ceph0)
1 | #scripts/rpc.py vhost_create_blk_controller --cpumask 0x1 vhost.1 Ceph1 |
qemu启动虚机,driver使用基于spdk的vhost-user-scsi技术, bdev backend为ceph rbd
创建vhost device (上文创建rbd dev名称为Ceph0)
1 | #scripts/rpc.py vhost_create_blk_controller --cpumask 0x1 vhost.1 Ceph1 |
1 | #scripts/rpc.py vhost_create_scsi_controller --cpumask 0x1 vhost.0 |
1 | qemu-system-x86_64 \ |
1 | qemu 使用 4.2.0 |
因虚拟机后端存储使用rbd, 所以下面spdk bdev 基于ceph rbd
导入ceph集群配置
1 | #vim /etc/ceph/conf.conf |
创建volume
1 | #rbd create volumes/volume-4431ef41-381e-490d-9976-adba14d2c05b --size 102400 |
删除volume
1 | #rpc.py bdev_rbd_delete Ceph0 |
resize volume
1 | #rpc.py bdev_rbd_resize Ceph0 102400 |
基于 CentOS 7 x86_64 安装spdk环境, 需要支持rbd和rdma
环境 : gcc-4.8.5
1 | #git clone https://github.com/spdk/spdk |
1 | sudo scripts/pkgdep.sh --all |
1 | ./configure --with-rbd --with-rdma --with-ocf |
1 | #HUGEMEM=4096 scripts/setup.sh |
1 | ./configure --with-rbd --with-rdma |
安装 librbd1-devel
下载docker镜像
1 | #docker pull docker.elastic.co/logstash/logstash:7.6.2 |
创建本地配置目录
1 | #mkdir /usr/local/logstash/config |
配置logstash.yml
1 | #vim /usr/local/logstash/config/logstash.yml |
随着5G、互联网、物联网等技术的发展, 对计算业务进行加速、卸载的需求日渐增多, Cyborg项目由此诞生。
Cyborg(以前叫做Nomad)是OpenStack用于管理硬件和软件加速资源框架, 包括GPU、FPGA、加解密卡, NVMe/NOF SSDs, ODP, DPDK/SPDK等, Cyborg就是OpenStack中的加速即服务(Acceleration as a Service)。该项目在OpenStack Q版本时正式发布, 由华为、联想、红帽主导,是一个很年轻的项目, 目前功能还不是很完善。
Cyborg通过管理、使用计算节点上的加速器硬件, 可以提供电信运营商在NFV以及边缘计算场景下的各种加速服务、提高用户体验、降低CPU负载。运维人员可以通过Cyborg列出、识别和发现加速器,挂载、卸载加速器实例, 安装、卸载驱动。它可以单独使用或与 Nova 或 Ironic 结合使用。
Cyborg采用经典架构,由cyborg-api、cyborg-conductor、cyborg-agent、 cyborg-db几个模块组成。其中Cyborg-agent位于计算节点,用于监控加速器;cyborg-conductor位于控制节点,管理整个系统和操作数据库。cyborg-api和cyborg-db分别为接口和数据库,均位于控制节点。
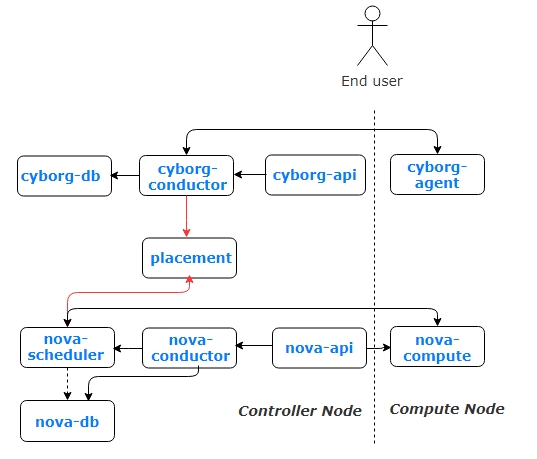
从Cyborg的架构图和API来看, 其主要工作流程如下:
cyborg-api会接收用户创建加速器的API调用, 通过cyborg-conductor保存到cyborg-db
cyborg-conductor通过rpc调用计算节点上的cyborg-agent, cyborg-agent会调用对应的厂商驱动, 最后由厂商驱动来执行配置计算节点底层的加速资源
计算节点上的cyborg-agent通过定时查询加速资源使用情况, 并通过API发送给placement服务, 该信息最终会给nova在调度时使用。
注: 由于加速设备可能存在多个设备互相关联的层次化结构, 如SRIOV PF和VF之间有关联关系。Nova在O版时, 为resource-providers数据库进行了扩展, 支持了设备的层次化关系。
http://specs.openstack.org/openstack/nova-specs/specs/ocata/approved/nested-resource-providers.html